

Artificial Intelligence has seen significant advancements over the years, with large language models (LLMs) at the forefront. DeepSeek R1, developed by DeepSeek-AI, represents a groundbreaking innovation in reasoning and problem-solving capabilities for LLMs. With its state-of-the-art architecture, the model has emerged as a competitor to OpenAI’s o1, setting new benchmarks in the AI community. This article explores the technical intricacies, achievements, and implications of DeepSeek R1, offering a deep dive into its design, training methodologies, and applications.
1. Introduction to DeepSeek R1
DeepSeek R1 is the first-generation reasoning model from DeepSeek-AI. It builds upon the company’s earlier successes with the DeepSeek-V3 base model, leveraging innovative reinforcement learning (RL) techniques. DeepSeek R1’s two main versions, DeepSeek R1-Zero and DeepSeek R1, reflect a meticulous approach to achieving unparalleled reasoning capabilities.
-
DeepSeek R1-Zero: This model is trained solely through large-scale RL without supervised fine-tuning (SFT). It demonstrates remarkable reasoning behaviors, such as self-verification and reflection, but struggles with readability and language mixing.
-
DeepSeek R1: To address these limitations, this version incorporates cold-start data and additional training steps to enhance performance, achieving results comparable to OpenAI’s o1.
Notably, DeepSeek R1 outperforms its peers in reasoning tasks, including math, coding, and scientific reasoning, while being open-source and accessible to the research community.
2. Key Features of DeepSeek R1
2.1 Post-Training with Reinforcement Learning
Unlike conventional models that rely heavily on supervised datasets, DeepSeek R1 adopts a pure RL-based approach. By directly applying RL to its base model (DeepSeek-V3), the team successfully trained DeepSeek R1-Zero to explore and refine reasoning patterns autonomously.
-
Chain-of-Thought (CoT) Reasoning: The model naturally generates step-by-step solutions for complex problems.
-
Self-Evolution: It learns to reassess its own outputs and improves over time without human intervention.
-
Sophisticated Behaviors: Reflection and reevaluation are emergent properties, making it highly effective in solving intricate tasks.
2.2 Cold-Start Data Integration
DeepSeek R1’s training pipeline includes supervised fine-tuning on carefully curated cold-start data. This step significantly enhances:
-
Readability: Ensures coherent and user-friendly responses.
-
Language Consistency: Mitigates the issue of mixed-language outputs during reasoning tasks.
-
Task-Specific Accuracy: Boosts performance on STEM, coding, and logical reasoning tasks.
2.3 Distillation for Smaller Models
DeepSeek R1 demonstrates that reasoning capabilities can be distilled into smaller models without compromising performance. The open-source release includes multiple distilled versions, ranging from 1.5B to 70B parameters, optimized for resource-constrained environments.
-
Qwen-Based Models: Models such as DeepSeek-R1-Distill-Qwen-32B outperform OpenAI’s o1-mini in key benchmarks.
-
Llama-Based Models: These models retain reasoning abilities while offering efficient deployment options.
3. Training Methodology
DeepSeek R1’s development involved a multi-stage pipeline, combining RL, SFT, and innovative data generation techniques. Let’s break down the process:
3.1 Reinforcement Learning (RL)
The core of DeepSeek R1’s success lies in its RL framework:
-
Group Relative Policy Optimization (GRPO): A cost-effective algorithm that eliminates the need for a critic model, relying on group-based scoring to optimize the policy model.
-
Reward Mechanisms: The model is trained using accuracy and format rewards, focusing on correct outputs and structured responses.
-
Aha Moments: During training, the model exhibits sudden improvements in reasoning abilities, such as rethinking its solutions and allocating more computation time to complex tasks.
3.2 Cold-Start Data
To address the limitations of R1-Zero, the team collected high-quality cold-start data:
-
Structure: Responses are designed to include both a reasoning process and a concise summary.
-
Curation: Data is manually refined to ensure readability and alignment with human preferences.
-
Impact: Cold-start fine-tuning significantly accelerated convergence and improved output quality.
3.3 Supervised Fine-Tuning (SFT)
After initial RL training, additional SFT is performed using:
-
Reasoning Data: Curated prompts and trajectories generated by rejection sampling.
-
Non-Reasoning Data: Includes writing, role-playing, and factual QA tasks to enhance general capabilities.
3.4 Distillation Process
The distilled models are fine-tuned on 800K samples generated by DeepSeek R1, covering reasoning and non-reasoning tasks. The process ensures that smaller models retain the reasoning prowess of their larger counterparts.
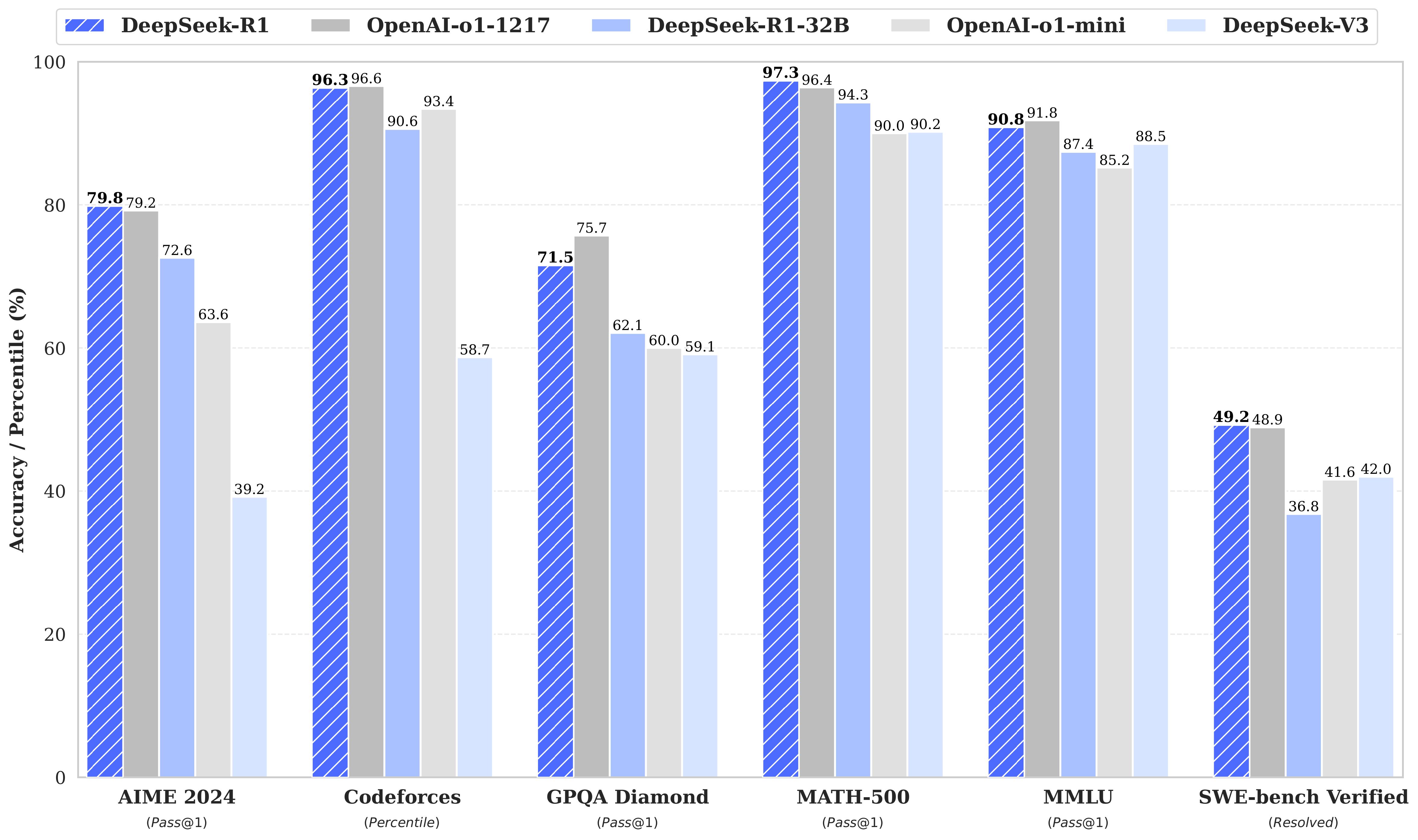
4. Evaluation and Benchmarks
DeepSeek R1 has been rigorously tested across a wide range of benchmarks, demonstrating its superiority in reasoning and general tasks. Key results include:
4.1 Reasoning Tasks
-
AIME 2024: Achieves a Pass@1 score of 79.8%, slightly surpassing OpenAI’s o1.
-
MATH-500: Scores 97.3%, outperforming all other models.
-
Codeforces: Achieves a 2029 Elo rating, placing it among the top performers in coding competitions.
4.2 General Knowledge
-
MMLU: Scores 90.8%, reflecting strong capabilities in STEM and humanities.
-
SimpleQA: Demonstrates superior accuracy in factual question answering.
-
FRAMES: Excels in long-context-dependent QA tasks, showcasing advanced document analysis skills.
4.3 Distilled Models
-
DeepSeek-R1-Distill-Qwen-32B: Achieves 94.3% on MATH-500 and 1691 Elo on Codeforces.
-
DeepSeek-R1-Distill-Llama-70B: Sets new benchmarks for dense models, rivaling larger models in reasoning tasks.
5. Applications of DeepSeek R1
DeepSeek R1’s advanced reasoning capabilities open up a plethora of applications across industries:
5.1 Education
-
Personalized Tutoring: Tailored explanations and problem-solving for students.
-
Content Generation: Creation of high-quality educational materials and practice problems.
5.2 Software Development
-
Code Generation: Efficiently generates and debugs code, reducing development time.
-
Engineering Support: Assists in solving complex algorithms and systems design problems.
5.3 Research and Analysis
-
Scientific Discovery: Facilitates hypothesis generation and data analysis in STEM fields.
-
Legal and Financial Analysis: Processes and interprets large volumes of text for legal and financial applications.
5.4 Creative Writing
-
Storytelling: Produces engaging and imaginative narratives.
-
Role-Playing: Enhances interactive experiences in gaming and simulations.
6. Community Impact and Accessibility
DeepSeek R1’s open-source nature sets it apart from many competitors. By releasing the model and its distilled versions under the MIT License, DeepSeek-AI has:
-
Empowered Researchers: Provided access to state-of-the-art reasoning tools.
-
Lowered Barriers: Enabled smaller organizations to leverage cutting-edge AI without significant costs.
-
Fostered Collaboration: Encouraged community-driven innovation and improvements.
7. Challenges and Future Directions
While DeepSeek R1 represents a significant leap forward, there are areas for improvement:
-
General Capabilities: Enhancing performance in multi-turn dialogues and complex role-playing scenarios.
-
Language Support: Addressing issues with language mixing and expanding support for non-English languages.
-
Software Engineering Tasks: Incorporating more training data to improve performance on engineering-related benchmarks.
-
Prompt Sensitivity: Developing robust prompting techniques to minimize performance variability.
DeepSeek-AI has outlined plans to address these challenges in future iterations, with a focus on leveraging long-chain reasoning and asynchronous evaluations.
8. Conclusion
DeepSeek R1 is a testament to the power of innovation and open collaboration in AI. By prioritizing reasoning capabilities through reinforcement learning and making the results accessible to the global community, DeepSeek-AI has set a new standard for LLMs. As the field of AI continues to evolve, models like DeepSeek R1 will undoubtedly play a pivotal role in shaping the future of intelligent systems.





