
Artificial intelligence continues to evolve at an extraordinary pace, and DeepSeek-V3 is the latest breakthrough to shake the AI landscape. Released in December 2024 by DeepSeek-AI, DeepSeek-V3 is a cutting-edge Mixture-of-Experts (MoE) language model with unprecedented performance and efficiency. This blog dives deep into the architecture, innovations, and potential applications of this remarkable model, demonstrating why it’s the most exciting development in AI today.
1. Introduction to DeepSeek-V3
DeepSeek-V3 is a revolutionary open-source MoE language model featuring 671 billion parameters in total, with 37 billion activated per token. Designed to optimize inference and training efficiency, it builds on the foundation of its predecessor, DeepSeek-V2, while introducing several pioneering techniques. These innovations include Multi-head Latent Attention (MLA), an auxiliary-loss-free load-balancing strategy, and a multi-token prediction (MTP) training objective.
Trained on 14.8 trillion high-quality tokens, DeepSeek-V3 underwent three key stages of training: pre-training, supervised fine-tuning, and reinforcement learning. Despite its massive scale and superior performance, the model required only 2.788 million H800 GPU hours for full training—a testament to its exceptional efficiency.
2. Architecture and Innovations
2.1 Mixture-of-Experts (MoE) Design
DeepSeek-V3 leverages an advanced MoE architecture that ensures only a subset of parameters (37 billion) are activated per token. This selective activation not only reduces computational overhead but also improves inference efficiency without compromising performance.
2.2 Auxiliary-Loss-Free Load Balancing
A standout feature of DeepSeek-V3 is its auxiliary-loss-free load-balancing strategy. Traditional MoE models often rely on auxiliary losses to balance the workload across experts, which can degrade performance. DeepSeek-V3 eliminates this need, enabling optimal load distribution while maintaining peak performance.
2.3 Multi-Token Prediction (MTP) Objective
The model introduces a novel MTP objective that enhances training efficiency and performance. By predicting multiple tokens simultaneously, MTP accelerates inference and opens the door for speculative decoding, further boosting processing speed.
3. Training Efficiency
DeepSeek-V3 sets a new standard for training efficiency through innovative techniques and hardware optimizations. Key highlights include:
-
FP8 Mixed Precision Training: The model validates the effectiveness of FP8 training on a massive scale, combining precision and efficiency.
-
Co-Design of Algorithms and Hardware: DeepSeek-AI’s collaboration with hardware vendors overcame communication bottlenecks in cross-node MoE training. This approach achieved near-total overlap between computation and communication, maximizing resource utilization.
-
Economical Training: Pre-training DeepSeek-V3 on 14.8 trillion tokens required just 2.664 million H800 GPU hours, with post-training stages adding only 0.1 million GPU hours. This efficiency allowed DeepSeek-AI to scale up the model size without incurring prohibitive costs.
4. Post-Training Advancements
DeepSeek-V3’s capabilities were further refined through knowledge distillation from the DeepSeek-R1 model series. This process incorporated advanced reasoning techniques, including verification and reflection patterns, into the model. The result is enhanced reasoning performance, as well as control over output style and length—key features for real-world applications.
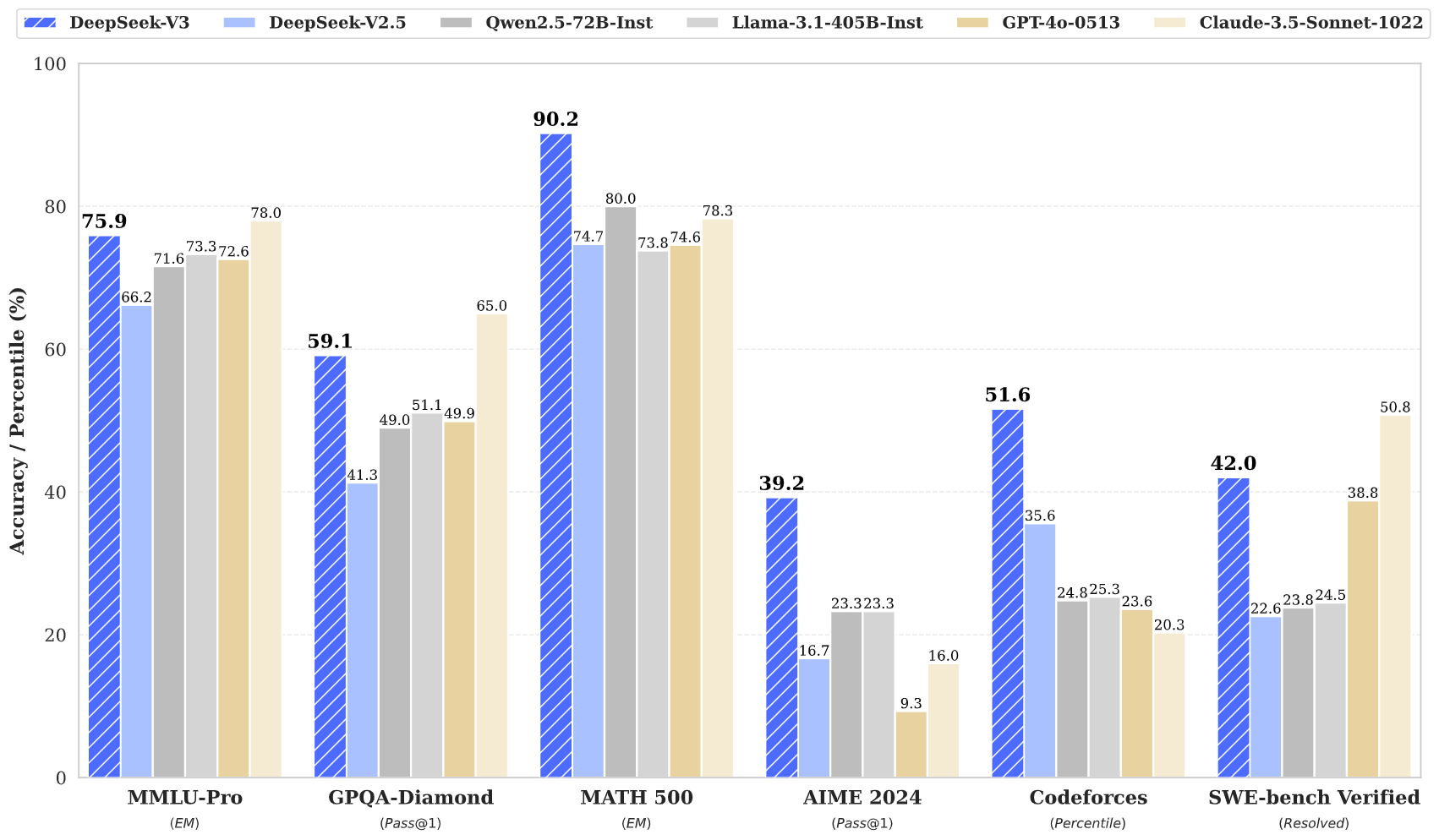
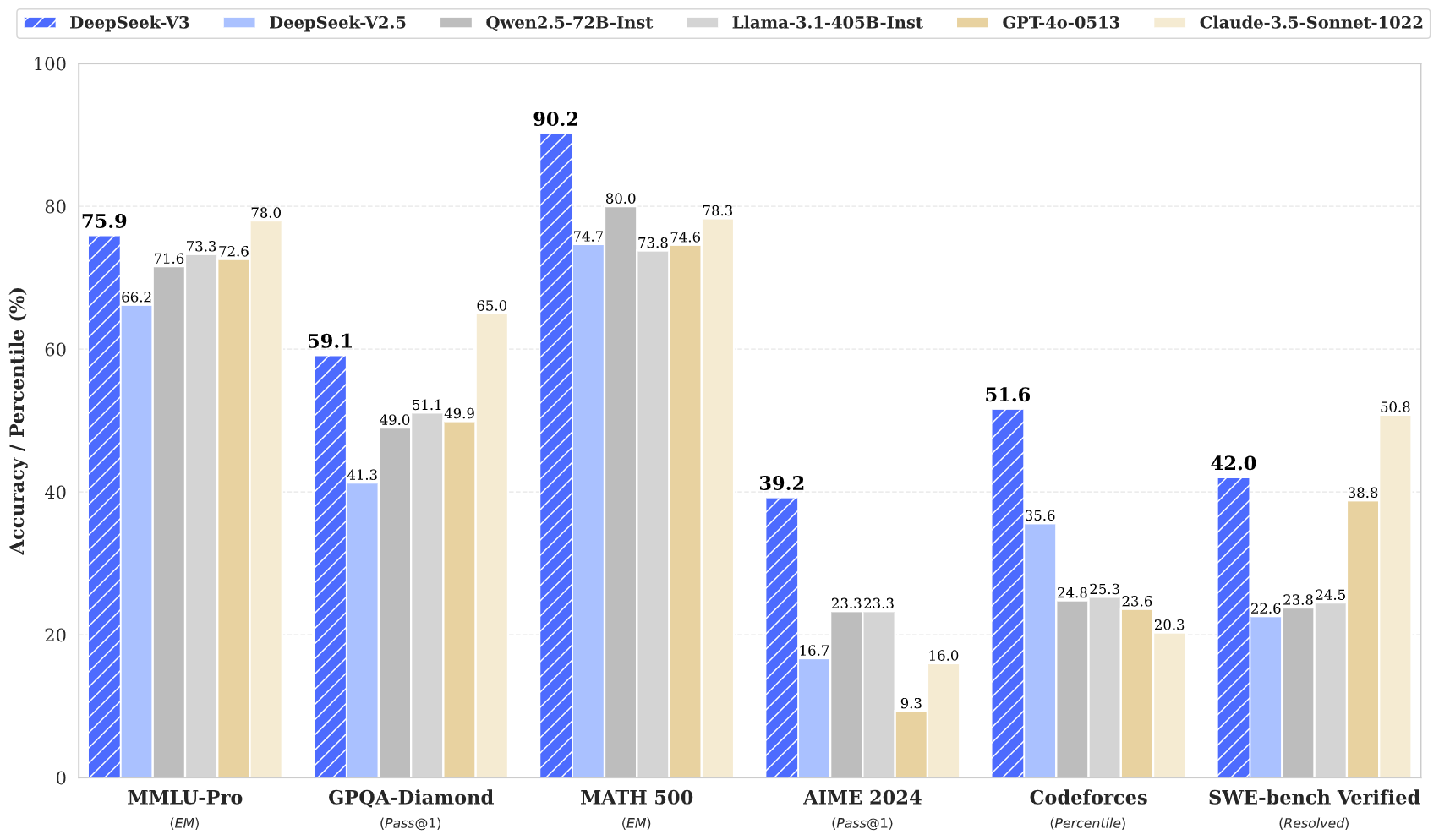
5. Evaluation and Benchmarking
DeepSeek-V3’s performance has been rigorously evaluated across various benchmarks, consistently outperforming other open-source models and rivaling leading closed-source alternatives. Here are some of the highlights:
5.1 Standard Benchmarks
-
MMLU (Acc.): Achieved 87.1% (5-shot), outperforming LLaMA 3.1 (84.4%) and Qwen 2.5 (85.0%).
-
BBH (EM): Scored 87.5%, surpassing competitors like DeepSeek-V2 (78.8%) and Qwen 2.5 (79.8%).
-
HellaSwag (Acc.): Delivered 88.9%, demonstrating strong natural language understanding capabilities.
5.2 Math and Reasoning Tasks
DeepSeek-V3 excels in math and reasoning benchmarks, setting new records in several categories:
-
GSM8K (EM): Achieved 89.3%, outperforming LLaMA 3.1 (83.5%).
-
MATH (EM): Scored 61.6%, a significant improvement over other models like Qwen 2.5 (54.4%).
-
MGSM (EM): Reached 79.8%, showcasing superior logical reasoning skills.
5.3 Code Generation
The model also shines in code-related tasks:
-
HumanEval (Pass@1): Achieved 65.2%, well ahead of LLaMA 3.1 (54.9%).
-
MBPP (Pass@1): Scored 75.4%, demonstrating strong programming capabilities.
6. Multilingual and Chinese Benchmarks
DeepSeek-V3’s multilingual capabilities are equally impressive:
-
MMMLU (non-English Acc.): Achieved 79.4%, outperforming Qwen 2.5 (74.8%).
-
C-Eval (Acc.): Scored 90.1%, setting a new standard for Chinese language tasks.
-
CMATH (EM): Delivered an outstanding 90.7%, showcasing its expertise in complex mathematical reasoning in Chinese.
7. Model Availability and Deployment
DeepSeek-V3 is available on Hugging Face, providing researchers and developers with easy access to its powerful capabilities. The total download size is 685 billion parameters, comprising 671 billion main model weights and 14 billion MTP module weights. Deployment options include support for NVIDIA, AMD GPUs, and Huawei Ascend NPUs, with comprehensive guidance provided in the README_WEIGHTS.md file.
8. Real-World Applications
DeepSeek-V3’s versatility makes it a valuable tool across various domains:
-
Natural Language Understanding: Ideal for tasks like sentiment analysis, summarization, and question answering.
-
Code Generation: A powerful assistant for developers, capable of generating, completing, and debugging code.
-
Mathematical Reasoning: Suitable for academic research, financial modeling, and complex problem-solving.
-
Multilingual Applications: Facilitates translation, cross-lingual information retrieval, and multilingual customer support.
9. Future Directions
DeepSeek-AI has laid the groundwork for ongoing innovation with DeepSeek-V3. The team is actively collaborating with the open-source community to enhance MTP module support and explore new applications. As the model evolves, it’s likely to inspire further advancements in AI research and development.
10. Conclusion
DeepSeek-V3 is more than just a language model; it’s a testament to what’s possible when cutting-edge technology meets efficient engineering. By combining state-of-the-art performance with unprecedented efficiency, DeepSeek-V3 sets a new benchmark for open-source AI. Whether you’re a researcher, developer, or AI enthusiast, this model represents an exciting opportunity to explore the future of artificial intelligence.



